一、Scrapy框架簡介與核心流程圖
Scrapy是一個(gè)基于Python開發(fā)的高效、快速的網(wǎng)絡(luò)爬蟲框架,廣泛應(yīng)用于數(shù)據(jù)抓取、信息提取和結(jié)構(gòu)化數(shù)據(jù)存儲。其設(shè)計(jì)遵循模塊化原則,使得開發(fā)者能夠靈活定制爬蟲流程。
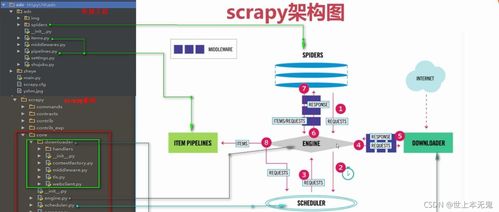
Scrapy核心架構(gòu)流程圖解析
Scrapy的工作流程可以概括為以下幾個(gè)關(guān)鍵步驟,形成一個(gè)清晰的閉環(huán)系統(tǒng):
- 引擎(Engine):作為整個(gè)框架的控制中心,負(fù)責(zé)調(diào)度所有組件之間的數(shù)據(jù)流。
- 調(diào)度器(Scheduler):接收引擎發(fā)來的請求(Request),并將其排隊(duì),等待引擎需要時(shí)再交還。
- 下載器(Downloader):根據(jù)引擎的指令,從互聯(lián)網(wǎng)上下載網(wǎng)頁內(nèi)容,并將響應(yīng)(Response)返回給引擎。
- 爬蟲(Spider):這是用戶編寫的核心邏輯部分。它負(fù)責(zé)解析下載器返回的響應(yīng),提取結(jié)構(gòu)化數(shù)據(jù)(Item)和新的后續(xù)請求(Request)。
- 項(xiàng)目管道(Item Pipeline):處理爬蟲提取到的Item。常見的操作包括數(shù)據(jù)清洗、驗(yàn)證、去重以及存儲到數(shù)據(jù)庫或文件中。
- 下載器中間件(Downloader Middlewares) 和 爬蟲中間件(Spider Middlewares):這兩個(gè)是鉤子框架,允許用戶自定義代碼,以全局方式處理請求和響應(yīng),例如添加代理、更換User-Agent等。
流程簡述:引擎從爬蟲獲取初始請求,交給調(diào)度器排隊(duì)。引擎再從調(diào)度器獲取請求,通過下載器中間件發(fā)送給下載器。下載器獲取網(wǎng)頁響應(yīng)后,通過引擎和爬蟲中間件傳遞給爬蟲。爬蟲解析響應(yīng),產(chǎn)生新的Items和Requests,Items交給管道處理,新的Requests則返回給引擎,開啟下一輪循環(huán)。
二、Scrapy的智能化安裝工程
傳統(tǒng)的安裝方式可能涉及手動解決依賴和版本沖突。如今,我們可以利用現(xiàn)代Python包管理工具實(shí)現(xiàn)更智能、更便捷的安裝。
環(huán)境準(zhǔn)備
確保系統(tǒng)已安裝Python(建議3.6及以上版本)和pip包管理工具。
推薦安裝方法
1. 使用pip進(jìn)行基礎(chǔ)安裝(最常用)
打開終端(Windows為CMD或PowerShell,Mac/Linux為Terminal),執(zhí)行以下命令:
`bash
pip install scrapy
`
這是最直接的方式。pip會自動從Python官方包索引(PyPI)下載Scrapy及其所有核心依賴(如Twisted, lxml, pyOpenSSL等)。
2. 創(chuàng)建虛擬環(huán)境(最佳實(shí)踐)
為避免項(xiàng)目間的包版本沖突,強(qiáng)烈建議在虛擬環(huán)境中安裝。
`bash
# 安裝虛擬環(huán)境管理工具(如果未安裝)
pip install virtualenv
# 為你的爬蟲項(xiàng)目創(chuàng)建一個(gè)新的虛擬環(huán)境
virtualenv scrapy_env
# 激活虛擬環(huán)境
Windows:
scrapy_env\Scripts\activate
# Mac/Linux:
source scrapy_env/bin/activate
# 在激活的虛擬環(huán)境中安裝Scrapy
pip install scrapy
`
3. 使用conda進(jìn)行科學(xué)計(jì)算環(huán)境集成安裝
如果你使用Anaconda或Miniconda進(jìn)行Python數(shù)據(jù)科學(xué)開發(fā),conda能更好地管理二進(jìn)制依賴。
`bash
conda install -c conda-forge scrapy
`
-c conda-forge指定從conda-forge社區(qū)頻道安裝,通常版本更新更快。
4. 驗(yàn)證安裝
安裝完成后,在命令行中輸入以下命令驗(yàn)證是否成功:
`bash
scrapy version
`
如果成功,將顯示已安裝的Scrapy版本號(例如 Scrapy 2.11.0)。
智能化安裝與問題解決
- 自動依賴解析:現(xiàn)代pip版本具備強(qiáng)大的依賴解析能力,能自動處理大部分兼容性問題。
- 使用pip install --upgrade pip:確保pip本身是最新版本,以獲得最佳的安裝體驗(yàn)和問題修復(fù)。
- 針對特定操作系統(tǒng)的預(yù)編譯包:在Windows上,如果安裝Twisted(Scrapy的核心依賴之一)失敗,可以訪問Unofficial Windows Binaries for Python Extension Packages網(wǎng)站,手動下載對應(yīng)Python版本的Twisted的.whl文件,然后通過pip install 下載的文件名.whl進(jìn)行安裝,再重新安裝Scrapy。
- 鏡像加速:在國內(nèi),可以使用清華大學(xué)、阿里云等PyPI鏡像源來大幅提升下載速度。
`bash
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
`
通過理解Scrapy的清晰架構(gòu)流程,并采用上述智能化的安裝方法,你可以快速、無痛地搭建起強(qiáng)大的爬蟲開發(fā)環(huán)境,從而更專注于爬蟲業(yè)務(wù)邏輯的實(shí)現(xiàn)。









